DSLab WNE UW

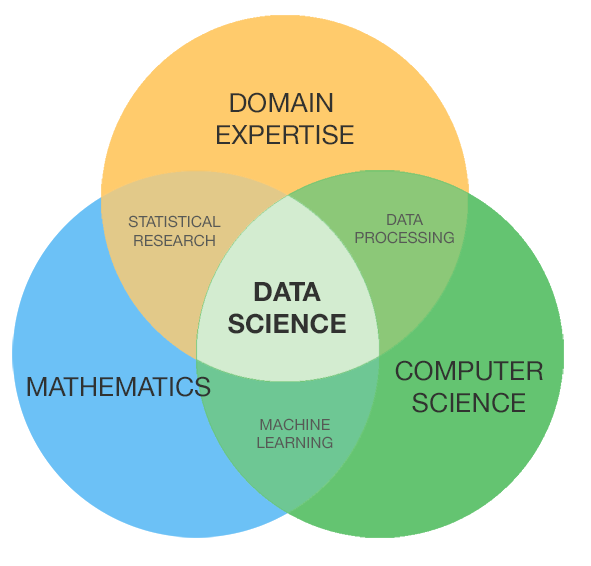
Czym jest Data Science?
Data Science to połączenie różnych narzędzi, algorytmów i metod uczenia maszynowego w celu odkrycia ukrytych wzorców na podstawie surowych danych.
W opozycji do Analityka Danych, który zwykle tylko powierzchownie wyjaśnia, co się dzieje w danych, Data Scientist nie tylko przeprowadza dogłębną analizę eksploracyjną, statystyczna i ekonometryczną aby dojść do jakiś wniosków, ale także wykorzystuje różne zaawansowane algorytmy uczenia maszynowego do identyfikowania możliwości wystąpienia określonego zdarzenia w przyszłości.
W skrócie, Data Science jest przede wszystkim wykorzystywane do wnikliwej analizy danych, pomagania przy podejmowaniu decyzji biznesowych, oraz prognoz z wykorzystaniem predykcyjnej analizy przyczynowej, analizy preskryptywnej (predykcyjna plus nauka decyzyjna) i uczenia maszynowego.
Data Science to połączenie różnych narzędzi, algorytmów i metod uczenia maszynowego w celu odkrycia ukrytych wzorców na podstawie surowych danych.
Kim jest Data Scientist?
Data Scientist jest osobą wszechstronną, czasami określaną jako tzw. Hybryda czyli połączenie kompetencji specjalistów paru dziedzin w jedną. Musi odznaczać się on nie tylko doskonałą wiedzą z zakresu statystyki, ekonometrii, technik komputerowych i programowania, ale także powinien posiadać kompetencje miękkie, które pozwolą mu efektywnie przewodzić zespołowi badawczemu lub prezentować otrzymane wyniki.
Cykl Życia Projektu Data Science
1. Faza Początkowa: Przed rozpoczęciem projektu ważne jest zrozumienie różnych specyfikacji, wymagań, priorytetów i budżetu. W tym etapie ocenie podlega, czy posiadasz wymagane zasoby, zarówno ludzkie jak i technologiczne do wsparcia projektu. Na tym etapie trzeba także sformułować problem biznesowy i wstępne hipotezy do późniejszego przetestowania.
2. Przygotowanie danych: Na tym etapie należy zbadać, wstępnie przetworzyć i ujednolicić dane przed modelowaniem. Faza ta zajmuje najwięcej czasu i jest również najbardziej wymagającą, głównie z uwagi na fakt, że trzeba jak najlepiej zrozumieć swoje dane.
3. Planowanie modelu: W tym miejscu musisz określić metody i techniki, które bedą wykorzystywane przy tworzeniu modelu, przydatna w tym celu okazuje się EDA (Exploratory Data Analysis) i wstępna wizualizacja danych. Te relacje będą stanowić podstawę dla algorytmów, które zostaną wdrożone w następnej fazie.
4. Budowanie modelu: W tej fazie dzieli się nasz zestaw danych na te, które posłużą do jego trenowania i testowania. Trzeba tutaj przeanalizować różne techniki uczenia maszynowego i wybrać taką, która będzie najlepsza pod kątem naszych danych. Takimi metodami mogą być np. klasyfikacja, asocjacja i grupowanie, regresja, sieci neuronowe itd.
5. Operacjonalizacja: Na tym etapie trzeba stworzyć raporty końcowe, opisać kody i przygotować dokumenty techniczne. Ponadto czasami warto jest wdrożyć projekt pilotażowy, który pozwoli nam sprawdzić jak nasz model zachowa się w środowisku produkcyjnym w czasie rzeczywistym. Zapewni to jasny obraz wydajności i innych powiązanych ograniczeń na małą skalę przed pełnym wdrożeniem.
6. Prezentacja Wyników: Jest to ostatni etap, który pozwala jednoznacznie ocenić, czy udało się osiągnąć założony cel. Identyfikuje się tutaj wszystkie kluczowe ustalenia dotyczące projektu, sprawdza czy projekt spełnił oczekiwania interesariuszy, a także czy osiągnięty rezultat należy uznać za sukces lub porażkę w oparciu o kryteria opracowane w fazie 1.

Metody Data Science
Machine Learning
Uczenie maszynowe to dziedzina na pograniczu technik komputerowych i statystyki, zaliczana do większej grupy potocznie nazywaną sztuczną inteligencją, która w swej prostocie, a zarazem złożoności, pozwala wykorzystywać złożone algorytmy w celu „nauki maszyn” zdobywania nowej wiedzy i umiejętności oraz wykorzystywania obecnej.
Uczenie maszynowe jest szeroko stosowane w eksploracji danych, wizji komputerowej, przetwarzaniu języka naturalnego, biometrii, wyszukiwarkach, diagnostyce medycznej, wykrywaniu oszustw kredytowych, analizie rynku papierów wartościowych, sekwencjonowaniu DNA, rozpoznawaniu mowy i pisma ręcznego, grach strategicznych i robotyce.
Machine Learning
Uczenie nadzorowane (Supervise Learning): Dane wejściowe są oznaczone, gdzie podczas procesu uczenia, porównuje się przewidywane wyniki z rzeczywistymi wynikami „danych treningowych” (tj. Danych wejściowych) i stale dostosowuje model predykcyjny, aż prognozowane wyniki modelu osiągną oczekiwaną dokładność.
Typowe algorytmy obejmują:
- Drzewa decyzyjne (np. Random Forest)
- Klasyfikację bayesowską (np. KNN)
- Regresję metodą najmniejszych kwadratów (np. OLS)
- Regresję logistyczną (np. Logit)
- Support Vector Machines
- Sieci neuronowe (np. Convolutional Neural Networks)
Uczenie nienadzorowane (Unsupervised Learning): Dane wejściowe nie mają znaczników, a co za tym idzie, wykorzystuje się algorytmy do automatycznego wnioskowania o wewnętrznych zależnościach danych, takich jak np klastrowanie.
Uczenie częściowo nadzorowane (Semi-Supervised Learning): Znaczniki części danych wejściowych są rozszerzeniem uczenia nadzorowanego, często stosowanym do klasyfikacji i regresji. Do typowych algorytmów należą algorytmy wnioskowania teorii grafów etc.
Reinforcement Learning: Dane wprowadza się jako informację zwrotną do modelu, podkreślając jak model powinien działać w oparciu o środowisko, aby zmaksymalizować oczekiwane korzyści. Różnica między Uczeniem Nadzorowanym (Supervised Learning) a Reinforcement Learning polega na tym, że nie wymaga prawidłowych par wejścia / wyjścia i nie wymaga precyzyjnej korekty nieoptymalnego zachowania.
Czym jest Data Science?
Data Science to połączenie różnych narzędzi, algorytmów i metod uczenia maszynowego w celu odkrycia ukrytych wzorców na podstawie surowych danych.
W opozycji do Analityka Danych, który zwykle tylko powierzchownie wyjaśnia, co się dzieje w danych, Data Scientist nie tylko przeprowadza dogłębną analizę eksploracyjną, statystyczna i ekonometryczną aby dojść do jakiś wniosków, ale także wykorzystuje różne zaawansowane algorytmy uczenia maszynowego do identyfikowania możliwości wystąpienia określonego zdarzenia w przyszłości.
W skrócie, Data Science jest przede wszystkim wykorzystywane do wnikliwej analizy danych, pomagania przy podejmowaniu decyzji biznesowych, oraz prognoz z wykorzystaniem predykcyjnej analizy przyczynowej, analizy preskryptywnej (predykcyjna plus nauka decyzyjna) i uczenia maszynowego.
Data Science to połączenie różnych narzędzi, algorytmów i metod uczenia maszynowego w celu odkrycia ukrytych wzorców na podstawie surowych danych.
Kim jest Data Scientist?
Data Scientist jest osobą wszechstronną, czasami określaną jako tzw. Hybryda czyli połączenie kompetencji specjalistów paru dziedzin w jedną. Musi odznaczać się on nie tylko doskonałą wiedzą z zakresu statystyki, ekonometrii, technik komputerowych i programowania, ale także powinien posiadać kompetencje miękkie, które pozwolą mu efektywnie przewodzić zespołowi badawczemu lub prezentować otrzymane wyniki.
Cykl Życia Projektu Data Science
1. Faza Początkowa: Przed rozpoczęciem projektu ważne jest zrozumienie różnych specyfikacji, wymagań, priorytetów i budżetu. W tym etapie ocenie podlega, czy posiadasz wymagane zasoby, zarówno ludzkie jak i technologiczne do wsparcia projektu. Na tym etapie trzeba także sformułować problem biznesowy i wstępne hipotezy do późniejszego przetestowania.
2. Przygotowanie danych: Na tym etapie należy zbadać, wstępnie przetworzyć i ujednolicić dane przed modelowaniem. Faza ta zajmuje najwięcej czasu i jest również najbardziej wymagającą, głównie z uwagi na fakt, że trzeba jak najlepiej zrozumieć swoje dane.
3. Planowanie modelu: W tym miejscu musisz określić metody i techniki, które bedą wykorzystywane przy tworzeniu modelu, przydatna w tym celu okazuje się EDA (Exploratory Data Analysis) i wstępna wizualizacja danych. Te relacje będą stanowić podstawę dla algorytmów, które zostaną wdrożone w następnej fazie.
4. Budowanie modelu: W tej fazie dzieli się nasz zestaw danych na te, które posłużą do jego trenowania i testowania. Trzeba tutaj przeanalizować różne techniki uczenia maszynowego i wybrać taką, która będzie najlepsza pod kątem naszych danych. Takimi metodami mogą być np. klasyfikacja, asocjacja i grupowanie, regresja, sieci neuronowe itd.
5. Operacjonalizacja: Na tym etapie trzeba stworzyć raporty końcowe, opisać kody i przygotować dokumenty techniczne. Ponadto czasami warto jest wdrożyć projekt pilotażowy, który pozwoli nam sprawdzić jak nasz model zachowa się w środowisku produkcyjnym w czasie rzeczywistym. Zapewni to jasny obraz wydajności i innych powiązanych ograniczeń na małą skalę przed pełnym wdrożeniem.
6. Prezentacja Wyników: Jest to ostatni etap, który pozwala jednoznacznie ocenić, czy udało się osiągnąć założony cel. Identyfikuje się tutaj wszystkie kluczowe ustalenia dotyczące projektu, sprawdza czy projekt spełnił oczekiwania interesariuszy, a także czy osiągnięty rezultat należy uznać za sukces lub porażkę w oparciu o kryteria opracowane w fazie 1.
Metody Data Science
Machine Learning
Uczenie maszynowe to dziedzina na pograniczu technik komputerowych i statystyki, zaliczana do większej grupy potocznie nazywaną sztuczną inteligencją, która w swej prostocie, a zarazem złożoności, pozwala wykorzystywać złożone algorytmy w celu „nauki maszyn” zdobywania nowej wiedzy i umiejętności oraz wykorzystywania obecnej.
Uczenie maszynowe jest szeroko stosowane w eksploracji danych, wizji komputerowej, przetwarzaniu języka naturalnego, biometrii, wyszukiwarkach, diagnostyce medycznej, wykrywaniu oszustw kredytowych, analizie rynku papierów wartościowych, sekwencjonowaniu DNA, rozpoznawaniu mowy i pisma ręcznego, grach strategicznych i robotyce.
Machine Learning
Uczenie nadzorowane (Supervise Learning): Dane wejściowe są oznaczone, gdzie podczas procesu uczenia, porównuje się przewidywane wyniki z rzeczywistymi wynikami „danych treningowych” (tj. Danych wejściowych) i stale dostosowuje model predykcyjny, aż prognozowane wyniki modelu osiągną oczekiwaną dokładność.
Typowe algorytmy obejmują:
- Drzewa decyzyjne (np. Random Forest)
- Klasyfikację bayesowską (np. KNN)
- Regresję metodą najmniejszych kwadratów (np. OLS)
- Regresję logistyczną (np. Logit)
- Support Vector Machines
- Sieci neuronowe (np. Convolutional Neural Networks)
Uczenie nienadzorowane (Unsupervised Learning): Dane wejściowe nie mają znaczników, a co za tym idzie, wykorzystuje się algorytmy do automatycznego wnioskowania o wewnętrznych zależnościach danych, takich jak np klastrowanie.
Uczenie częściowo nadzorowane (Semi-Supervised Learning): Znaczniki części danych wejściowych są rozszerzeniem uczenia nadzorowanego, często stosowanym do klasyfikacji i regresji. Do typowych algorytmów należą algorytmy wnioskowania teorii grafów etc.
Reinforcement Learning: Dane wprowadza się jako informację zwrotną do modelu, podkreślając jak model powinien działać w oparciu o środowisko, aby zmaksymalizować oczekiwane korzyści. Różnica między Uczeniem Nadzorowanym (Supervised Learning) a Reinforcement Learning polega na tym, że nie wymaga prawidłowych par wejścia / wyjścia i nie wymaga precyzyjnej korekty nieoptymalnego zachowania.
Spodobały ci się nasze projekty? Masz pomysł na własny?
Biuro
Długa 44/50, 00-241 Warszawa
Godziny
Pon - Pt: 9.00 - 17.00
Sob - Nd: Zamknięte
Kontakt
dr Piotr Wójcik