DSLab WNE UW

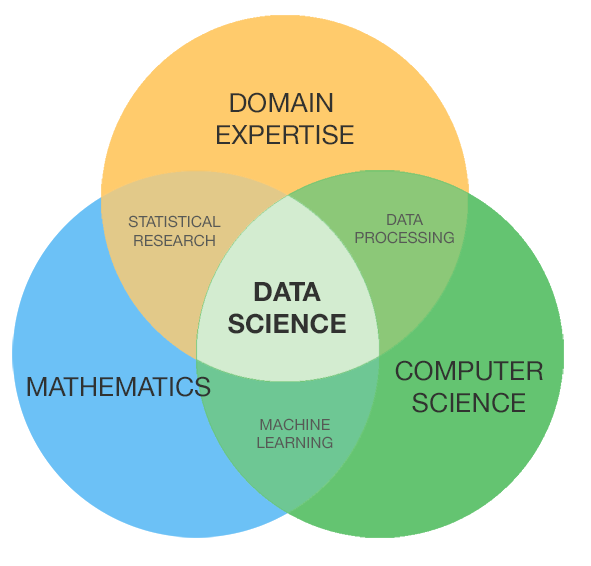
What is Data Science?
Data Science is a combination of various tools, algorithms and machine learning methods to discover hidden patterns based on raw data.
In opposition to the Data Analyst, who usually only superficially explains what is happening in the data, Data Scientist not only performs in-depth exploratory, statistical and econometric analysis to arrive at any conclusions, but also uses various advanced machine learning algorithms to identify the possibility of a specific event occurring in the future.
In short, Data Science is primarily used for in-depth data analysis, helping in making business decisions, and forecasts using predictive causal analysis, prescriptive analysis (predictive plus decision science), and machine learning.
Data Science is a combination of various tools, algorithms and machine learning methods to discover hidden patterns based on raw data.
Who is a Data Scientist?
A Data Scientist is a versatile person, sometimes referred to as the so-called Hybrid or a combination of the competence of specialists in several fields into one. He must have not only excellent knowledge of statistics, econometrics, computer techniques and programming, but also should have soft skills that will allow him to effectively lead the research team or present the results obtained.
Data Science Project Life Cycle
1. Initial Phase: Before starting a project, it is important to understand the various specifications, requirements, priorities and budget. At this stage, it is assessed whether you have the required resources, both human and technological, to support the project. At this stage, you also need to formulate a business problem and preliminary hypotheses for later testing.
2. Data preparation: At this stage, data should be explored, pre-processed and standardized before modeling. This phase takes the most time and is also the most demanding, mainly due to the fact that you need to understand your data as best as possible.
3. Model planning: Here you need to specify the methods and techniques that will be used to create the model, EDA (Exploratory Data Analysis) and initial data visualization are useful for this purpose. These relationships will form the basis for the algorithms that will be implemented in the next phase.
4. Model building: In this phase, our data set is divided into those that will be used to train and test it. Here you have to analyze various machine learning techniques and choose the one that will be the best in terms of our data. Such methods can be e.g. classification, association and grouping, regression, neural networks etc.
5. Operationalization: At this stage you need to create final reports, describe the codes and prepare technical documents. In addition, sometimes it is worth implementing a pilot project that will allow us to check how our model will behave in a production environment in real time. This will provide a clear picture of performance and other related limitations on a small scale before being fully implemented.
6. Presentation of Results: This is the last stage that allows you to clearly assess whether you have achieved your goal. All key project arrangements are identified here, whether the project has met stakeholder expectations, and whether the result should be considered a success or failure based on the criteria developed in phase 1.

Data Science methods
Machine Learning
Machine learning is a field on the borderline between computer techniques and statistics, included in a larger group commonly referred to as artificial intelligence, which in its simplicity and complexity allows the use of complex algorithms to “learn machines” to acquire new knowledge and skills and to use current.
Machine learning is widely used in data mining, computer vision, natural language processing, biometrics, search engines, medical diagnostics, credit fraud detection, stock market analysis, DNA sequencing, speech and handwriting recognition, strategy games and robotics.
Machine Learning is
Supervise Learning: Input data is marked where, during the learning process, the predicted results are compared with the actual results of the “training data” (ie, the Input Data) and constantly adjusts the predictive model until the predicted model results reach the expected accuracy.
Typical algorithms include:
- Decision trees (e.g. Random Forest)
- Bayesian classification (e.g. KNN)
- Least squares regression (e.g. OLS)
- Logistic regression (e.g. Logit)
- Support Vector Machines
- Neural networks (e.g. Convolutional Neural Networks)
Unsupervised Learning: The input data has no tags, and therefore, algorithms are used to automatically infer internal data dependencies, such as clustering.
Semi-Supervised Learning: Part input markers are an extension of supervised learning, often used for classification and regression. Typical algorithms include inference algorithms for graph theory etc.
Reinforcement Learning:Data is introduced as feedback to the model, highlighting how the model should operate based on the environment to maximize the expected benefits. The difference between Supervised Learning and Reinforcement Learning is that it does not require valid I / O pairs and does not require precise correction of non-optimal behavior.
What is Data Science?
Data Science is a combination of various tools, algorithms and machine learning methods to discover hidden patterns based on raw data.
In opposition to the Data Analyst, who usually only superficially explains what is happening in the data, Data Scientist not only performs in-depth exploratory, statistical and econometric analysis to arrive at any conclusions, but also uses various advanced machine learning algorithms to identify the possibility of a specific event occurring in the future.
In short, Data Science is primarily used for in-depth data analysis, helping in making business decisions, and forecasts using predictive causal analysis, prescriptive analysis (predictive plus decision science), and machine learning.
Data Science is a combination of various tools, algorithms and machine learning methods to discover hidden patterns based on raw data.
Who is a Data Scientist?
A Data Scientist is a versatile person, sometimes referred to as the so-called Hybrid or a combination of the competence of specialists in several fields into one. He must have not only excellent knowledge of statistics, econometrics, computer techniques and programming, but also should have soft skills that will allow him to effectively lead the research team or present the results obtained.
Data Science Project Life Cycle
1. Initial Phase: Before starting a project, it is important to understand the various specifications, requirements, priorities and budget. At this stage, it is assessed whether you have the required resources, both human and technological, to support the project. At this stage, you also need to formulate a business problem and preliminary hypotheses for later testing.
2. Data preparation: At this stage, data should be explored, pre-processed and standardized before modeling. This phase takes the most time and is also the most demanding, mainly due to the fact that you need to understand your data as best as possible.
3. Model planning: Here you need to specify the methods and techniques that will be used to create the model, EDA (Exploratory Data Analysis) and initial data visualization are useful for this purpose. These relationships will form the basis for the algorithms that will be implemented in the next phase.
4. Model building: In this phase, our data set is divided into those that will be used to train and test it. Here you have to analyze various machine learning techniques and choose the one that will be the best in terms of our data. Such methods can be e.g. classification, association and grouping, regression, neural networks etc.
5. Operationalization: At this stage you need to create final reports, describe the codes and prepare technical documents. In addition, sometimes it is worth implementing a pilot project that will allow us to check how our model will behave in a production environment in real time. This will provide a clear picture of performance and other related limitations on a small scale before being fully implemented.
6. Presentation of Results: This is the last stage that allows you to clearly assess whether you have achieved your goal. All key project arrangements are identified here, whether the project has met stakeholder expectations, and whether the result should be considered a success or failure based on the criteria developed in phase 1.
Data Science methods
Machine Learning
Machine learning is a field on the borderline between computer techniques and statistics, included in a larger group commonly referred to as artificial intelligence, which in its simplicity and complexity allows the use of complex algorithms to “learn machines” to acquire new knowledge and skills and to use current.
Machine learning is widely used in data mining, computer vision, natural language processing, biometrics, search engines, medical diagnostics, credit fraud detection, stock market analysis, DNA sequencing, speech and handwriting recognition, strategy games and robotics.
Machine Learning is
Supervise Learning: Input data is marked where, during the learning process, the predicted results are compared with the actual results of the “training data” (ie, the Input Data) and constantly adjusts the predictive model until the predicted model results reach the expected accuracy.
Typical algorithms include:
- Decision trees (e.g. Random Forest)
- Bayesian classification (e.g. KNN)
- Least squares regression (e.g. OLS)
- Logistic regression (e.g. Logit)
- Support Vector Machines
- Neural networks (e.g. Convolutional Neural Networks)
Unsupervised Learning: The input data has no tags, and therefore, algorithms are used to automatically infer internal data dependencies, such as clustering.
Semi-Supervised Learning: Part input markers are an extension of supervised learning, often used for classification and regression. Typical algorithms include inference algorithms for graph theory etc.
Reinforcement Learning:Data is introduced as feedback to the model, highlighting how the model should operate based on the environment to maximize the expected benefits. The difference between Supervised Learning and Reinforcement Learning is that it does not require valid I / O pairs and does not require precise correction of non-optimal behavior.
Do you like our projects? Do you have idea for your own project?
Office
Długa 44/50, 00-241 Warsaw, Poland
Hours
Mon-Fri: 9.00-17.00
Sat-Sun: Closed
Contact
Dr Piotr Wojcik